정부가 오는 6월부터 첨단 GPU 264장을 중소·벤처기업에 풀기로 했습니다. 엔비디아 B200이라는 칩인데, 국내에서 가장 비싼 축에 듭니다. NHN클라우드 위에 얹어서 제공하고, 선정되면 연말까지 무상입니다.
문제는 발표문입니다. "AI 전환 가속화", "초격차 스타트업", "기술 자립" 같은 말로 가득해서 막상 창업자는 헷갈립니다. 누구한테 주는 건지, 받으면 뭘 만들라는 건지 좀처럼 감이 오지 않습니다.
쉽게 풀어드리겠습니다. 매달 ChatGPT나 Claude에 결제하며 쓰고 계신가요? 그 일을 이번 기회에 정부 GPU 위로 옮기는 겁니다. 오픈소스 모델을 띄워서 자기만의 API로 돌리면 됩니다. 새 AI를 발명하는 팀이 아니라 오픈소스를 자기 업무에 끼워 쓰는 팀을 위한 자원입니다. 누가 받을 수 있고, 어떻게 준비해야 하는지 순서대로 풀어드리겠습니다.

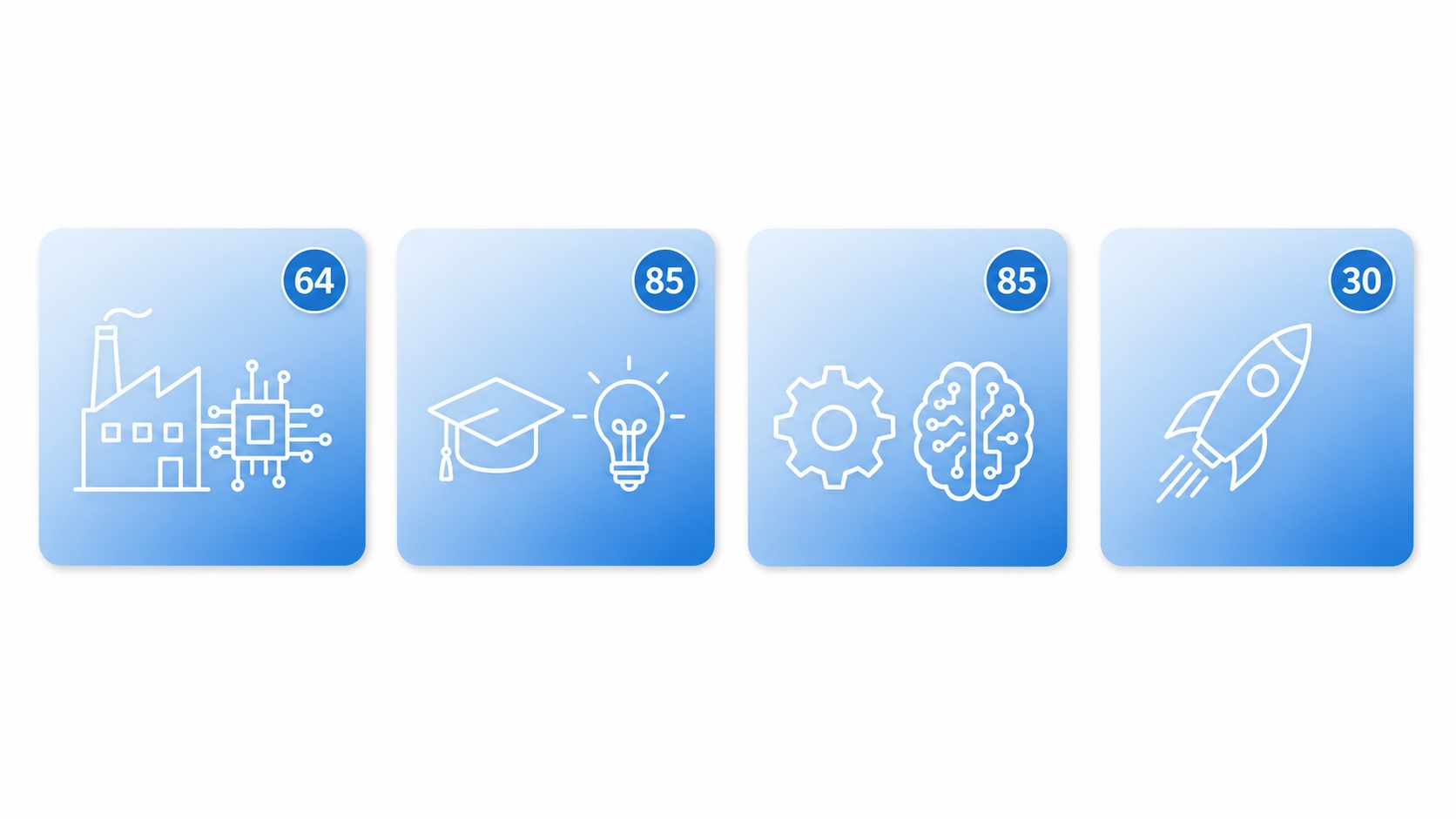
이번 공급은 크게 두 갈래로 나뉘고, 전체 물량은 264장입니다.
AI 에이전트 과제에 64장이 먼저 배정됐습니다. 기술기업과 제조기업이 컨소시엄을 꾸려야 신청할 수 있습니다. 초격차 과제는 다시 세 갈래로 나뉘는데요. 전략 AI 개발에는 85장이 걸려 있고 대학·출연연과 창업기업의 협업이 조건입니다. 산업 특화 AI 솔루션도 85장인데, 산업 도메인을 가진 회사와 AI 회사가 손을 잡아야 합니다. 마지막으로 모두의 창업 프로그램에 30장이 별도 배정돼 있습니다.
| 트랙 | GPU | 누가 받는가 |
|---|---|---|
| AI 에이전트 과제 | 64장 | 기술기업 + 제조기업 컨소시엄 |
| 초격차 — 전략 AI 개발 | 85장 | 대학·출연연 + 창업기업 협업 |
| 초격차 — 산업 특화 AI 솔루션 | 85장 | 기업 간 협업 (산업 + AI) |
| 초격차 — 모두의 창업 | 30장 | '모두의 창업' 프로그램 별도 배정 |
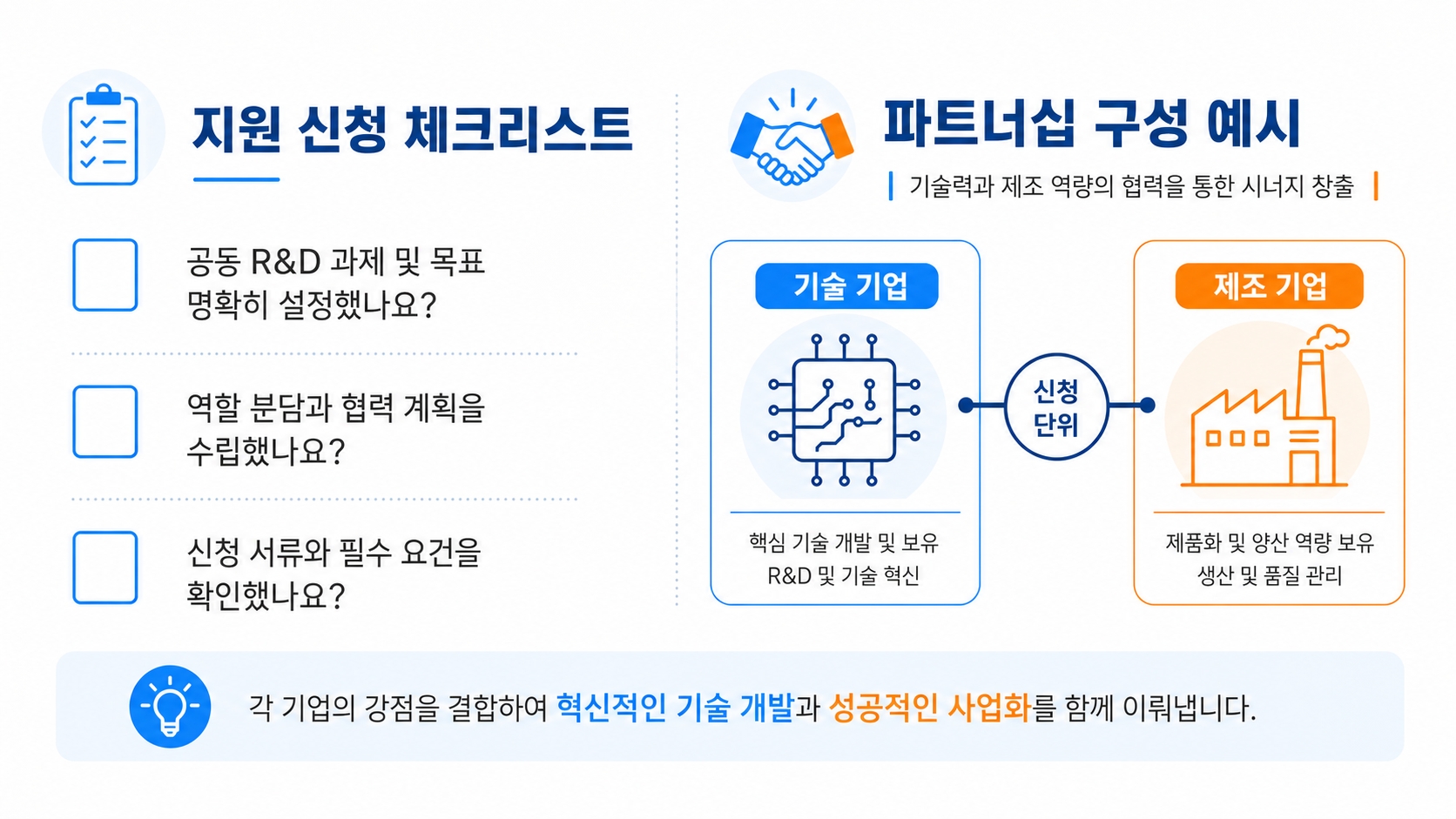
여기서 한 가지 짚고 넘어가야 할 대목이 있습니다. 모든 트랙이 혼자 받는 구조가 아니라 둘 이상이 묶여서 받는 구조라는 점입니다. 기술기업 혼자도 안 되고, 제조기업 혼자도 안 되고, 대학 혼자도 안 됩니다. 누구와 짝을 짓느냐가 신청서의 절반을 차지하는 이유입니다.
GPU 사용 방식은 의외로 간단합니다. 사무실에 칩이 배달되는 게 아니라, NHN클라우드 계정으로 원격 접속해서 쓰는 겁니다. NHN이 호텔이고 GPU가 방이라고 생각하면 이해하기 쉽습니다. 신청자는 자기 모델과 데이터, 코드를 들고 들어가서 작업하는 손님이 되는 셈이죠.
이 트랙에 가장 잘 맞는 분들: AI를 자기 산업에 적용하고 싶은데 매달 API 결제 비용이 부담되거나, 데이터 보안 때문에 외부 서비스를 못 쓰던 팀.도움이 가장 절실해지는 시점: GPU는 받았지만 자기 도메인 데이터를 정제할 인력이 없는 때.

가장 많이들 헷갈리는 지점부터 바로잡겠습니다. 이 정책은 새 AI를 처음부터 학습하라는 뜻이 아닙니다.
GPT나 Claude 같은 파운데이션 모델을 처음부터 학습하려면 GPU가 수만 장은 있어야 합니다. 264장으로는 물리적으로 불가능한 일입니다. 정책의 규모 자체가 애초에 응용을 염두에 둔 거지, 모델 학습을 위한 게 아닙니다. 그래서 실제 작업 비중을 들여다보면 그림이 선명해집니다. 가장 큰 비중을 차지하는 건 RAG입니다. 오픈소스 모델에 자기 회사 문서와 벡터DB를 붙여서 쓰는 방식이죠. 그다음이 에이전트 시스템이고, LoRA나 어댑터 같은 가벼운 파인튜닝이 일부 뒤를 잇습니다. 모델 전체를 다시 학습시키는 풀 파인튜닝은 극소수에 그칠 전망이고, 처음부터 모델을 새로 만드는 경우는 사실상 없다고 봐도 됩니다.
모델은 거의 100% 오픈소스를 가져옵니다. 국내 스타트업들이 가장 많이 쓰는 건 딥시크 R1·V3, 큐웬 2.5·3, Llama 3.1·3.3 세 종류로 압축됩니다. 추론이 강하고 비용이 저렴한 쪽을 원하면 딥시크, 멀티모달과 코딩에서 강점을 살리고 싶다면 큐웬, 안정성과 라이선스를 중시한다면 Llama 순으로 고르면 됩니다.
한 가지 더 덧붙이자면, CUDA 코드는 한 줄도 짤 필요가 없습니다. 신청 팀이 손대는 레이어는 거의 파이썬 프레임워크 위에서 돌아갑니다. CUDA와 드라이버, 인퍼런스 엔진 같은 아래쪽은 엔비디아와 NHN, 오픈소스 커뮤니티가 이미 다 만들어 놓았기 때문입니다. 신청 팀이 진짜 신경 써야 할 건 자기 데이터, 자기 도메인 로직, 자기 시스템입니다.
무상은 GPU 시간이지,
시간 자체가 아닙니다.

GPU는 정부가 줍니다. 받았다고 저절로 돌아가는 시스템이 생기는 건 아닙니다. 우리가 현장에서 지켜본 바로는, 세 가지 문제가 유독 빨리 터져 나옵니다.
하나, 만들 손이 부족합니다GPU만 받는다고 시스템이 자동으로 생기지 않습니다. 누군가는 오픈소스 모델을 띄워야 하고, 자기 도메인 데이터를 정제해야 하고, RAG 파이프라인을 짜야 하고, 끝까지 운영도 가져가야 합니다. 그런데 AI 개발자는 대기업과 빅테크가 거의 다 데려갔습니다. 풀스택을 한꺼번에 묶어서 만들어줄 팀은 더 드뭅니다. 6월에 GPU를 받고, 7~8월에 환경을 갖추고 나면 바로 이 벽과 마주하게 됩니다.
둘, 시간이 넉넉하지 않습니다
무상 사용은 연말까지입니다. 6월에 받으면 실제 주어진 시간은 6~7개월 남짓. 이 안에 PoC 수준이 아니라 자기 산업에서 실제로 굴러가는 시스템까지 가야 합니다. 거기까지 못 가면 12월부터 GPU 사용료가 시장가로 청구됩니다. B200 한 장이면 시간당 수만 원에서 수십만 원으로 뜁니다. 무상인 건 GPU지, 시간이 아닙니다.
셋, 컨소시엄을 짜는 것 자체가 첫 관문입니다
AI 에이전트 64장은 기술기업과 제조기업이 함께 신청해야 합니다. 초격차 두 트랙도 구조는 마찬가지입니다. 혼자 넣을 수 있는 트랙이 사실상 없습니다. 누구와 짝을 지을지, 누구의 데이터를 쓸지, 누가 시스템을 만들고 누가 운영할지 — 이 역할 분담이 신청서의 절반입니다.
이런 문제들에 가장 취약한 팀: 정부 지원은 받았지만 기술 인력이 없는 1~2인 창업팀, 데이터 정제부터 서빙까지 끌고 갈 사람이 없는 팀, 제조 도메인은 강한데 기술 파트너가 없는 회사.
읽고만 있으면 까먹습니다. 지금 할 수 있는 것들을 정리했습니다.
첫째, 네 트랙 중 우리 회사가 어디에 맞는지 점검하세요제조회사인데 AI 도입이 필요하다면 AI 에이전트 64장 트랙에서 기술기업 파트너를 찾으면 됩니다. 기술회사라면 같은 트랙에서 제조기업과 손을 잡는 그림입니다. 산학 협업이 가능한 창업기업은 초격차 전략 AI 85장을, 산업 도메인과 AI 회사가 묶여 있다면 초격차 산업 솔루션 85장을 노려볼 만합니다. 1인이나 예비 단계라면 모두의 창업 30장이 출발점입니다.
둘째, 우리 도메인에 맞는 오픈소스 모델을 미리 골라 두세요
GPU 받고 나서 모델 고르기 시작하면 늦습니다. 우리 작업이 추론 위주라면 딥시크 R1, 다국어나 멀티모달이 필요하다면 큐웬, 라이선스 안전이 중요하다면 Llama를 먼저 살펴보세요. 모델 크기가 GPU 할당량과 맞는지, 회사 안에 학습이나 RAG에 쓸 자료가 충분한지도 함께 점검해야 합니다.
셋째, 5월 공모 전에 컨소시엄 짝을 정하세요
신청 단위가 컨소시엄인 이상, 4월 안에 짝을 찾고 5월에 함께 서류를 쓰는 일정이 가장 안전합니다. K-Startup 누리집에서 공고가 올라오는 즉시 마감일을 확인하세요. 5월을 놓치면 다음 기회는 분기 뒤가 아니라 1년 뒤일 수도 있습니다.

GPU는 정부가 준비했고, 모델은 오픈소스에 이미 나와 있고, 클라우드는 NHN이 깔아 두었습니다. 그런데도 결국 만드는 건 팀의 몫입니다.
지방과 중소기업, 초기 단계에서 AI를 자기 산업에 붙이려는 팀이 가장 먼저 부딪히는 벽은 하나로 요약됩니다. 자원은 손에 들어왔는데, 만들 손이 부족한 순간. 흐름소프트는 그 자리 옆에 있습니다. 제조 회사가 기술 파트너를 찾을 때, 산업 회사가 AI 시스템 운영자를 구할 때, 1~2인 창업팀이 RAG와 에이전트, 서빙까지 풀스택을 맡길 곳을 찾을 때 — 우리는 "견적 같이 짭시다"가 아니라 "같이 만듭시다"라고 말합니다. 그게 우리 방식입니다.